Notes on Git

文章目录
![]()
起步
Git 和其他版本控制系统的主要差别在于,Git 只关心文件数据的整体是否发生变化,而大多数其他系统则只关心文件内容的具体差异。这类系统(CVS,Subversion,Perforce,Bazaar 等等)每次记录有哪些文件作了更新,以及都更新了哪些行的什么内容。Git 并不保存这些前后变化的差异数据。实际上,Git 更像是把变化的文件作快照后,记录在一个微型的文件系统中。每次提交更新时,它会纵览一遍所有文件的指纹信息并对文件作一快照,然后保存一个指向这次快照的索引。为提高性能,若文件没有变化,Git 不会再次保存,而只对上次保存的快照作一链接。
在保存到 Git 之前,所有数据都要进行内容的校验和(checksum)计算,并将此结果作为数据的唯一标识和索引。换句话说,不可能在你修改了文件或目录之后,Git 一无所知。这项特性作为 Git 的设计哲学,建在整体架构的最底层。所以如果文件在传输时变得不完整,或者磁盘损坏导致文件数据缺失,Git 都能立即察觉。Git 使用 SHA-1 算法计算数据的校验和,通过对文件的内容或目录的结构计算出一个 SHA-1 哈希值,作为指纹字符串。该字串由 40 个十六进制字符(0-9 及 a-f)组成。Git 的工作完全依赖于这类指纹字串,所以你会经常看到这样的哈希值。实际上,所有保存在 Git 数据库中的东西都是用此哈希值来作索引的,而不是靠文件名。
常用的 Git 操作大多仅仅是把数据添加到数据库。因为任何一种不可逆的操作,比如删除数据,都会使回退或重现历史版本变得困难重重。在别的 VCS 中,若还未提交更新,就有可能丢失或者混淆一些修改的内容,但在 Git 里,一旦提交快照之后就完全不用担心丢失数据,特别是养成定期推送到其他仓库的习惯的话。
对于任何一个文件,在 Git 内都只有三种状态:已提交(committed),已修改(modified)和已暂存(staged)。已提交表示该文件已经被安全地保存在本地数据库中了;已修改表示修改了某个文件,但还没有提交保存;已暂存表示把已修改的文件放在下次提交时要保存的清单中。
每个项目都有一个 Git 目录(译注:如果 git clone 出来的话,就是其中 .git 的目录;如果 git clone –bare 的话,新建的目录本身就是 Git 目录。),它是 Git 用来保存元数据和对象数据库的地方。该目录非常重要,每次克隆镜像仓库的时候,实际拷贝的就是这个目录里面的数据。从项目中取出某个版本的所有文件和目录,用以开始后续工作的叫做工作目录。这些文件实际上都是从 Git 目录中的压缩对象数据库中提取出来的,接下来就可以在工作目录中对这些文件进行编辑。所谓的暂存区域只不过是个简单的文件,一般都放在 Git 目录中。有时候人们会把这个文件叫做索引文件,不过标准说法还是叫暂存区域。
Git 提供了一个叫做 git config 的工具(译注:实际是 git-config 命令,只不过可以通过 git 加一个名字来呼叫此命令。),专门用来配置或读取相应的工作环境变量。而正是由这些环境变量,决定了 Git 在各个环节的具体工作方式和行为。这些变量可以存放在以下三个不同的地方:
/etc/gitconfig文件:系统中对所有用户都普遍适用的配置。若使用git config时用--system选项,读写的就是这个文件。~/.gitconfig文件:用户目录下的配置文件只适用于该用户。若使用git config时用--global选项,读写的就是这个文件。- 当前项目的 git 目录中的配置文件(也就是工作目录中的
.git/config文件):这里的配置仅仅针对当前项目有效。每一个级别的配置都会覆盖上层的相同配置,所以.git/config里的配置会覆盖/etc/gitconfig中的同名变量。
要检查已有的配置信息,可以使用 git config --list 命令。
Git 基础
Git 支持许多数据传输协议。之前的例子使用的是 git:// 协议,不过你也可以用 http(s):// 或者 user@server:/path.git 表示的 SSH 传输协议。
工作目录下面的所有文件都不外乎这两种状态:已跟踪或未跟踪。已跟踪的文件是指本来就被纳入版本控制管理的文件,在上次快照中有它们的记录,工作一段时间后,它们的状态可能是未更新,已修改或者已放入暂存区。而所有其他文件都属于未跟踪文件。它们既没有上次更新时的快照,也不在当前的暂存区域。初次克隆某个仓库时,工作目录中的所有文件都属于已跟踪文件,且状态为未修改。
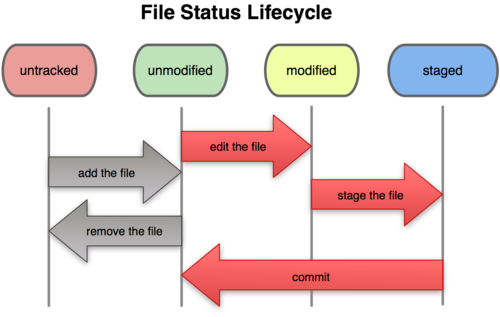
|
|
从上面可以看出,一个新的文件初始状态是untracked file,使用git add filename后进入unmodified状态,此时使用git rm filename可以退回到untracked状态,使用编辑器编辑之后,进入到modified状态,在modified状态,可以使用git checkout -- filename来回退到unmodified状态,使用git add filename进入到staged,to be commited状态,在staged状态,可以使用git reset HEAD filename回退到modified状态,也可以使用git commit filename -m "commit message"来进入git history,进入到unmodified状态。
其实 git add 的潜台词就是把目标文件快照放入暂存区域,也就是 add file into staged area,同时未曾跟踪过的文件标记为需要跟踪。
一般我们总会有些文件无需纳入 Git 的管理,也不希望它们总出现在未跟踪文件列表。通常都是些自动生成的文件,比如日志文件,或者编译过程中创建的临时文件等。我们可以创建一个名为 .gitignore 的文件,列出要忽略的文件模式。文件 .gitignore 的格式规范如下:
- 所有空行或者以注释符号 # 开头的行都会被 Git 忽略。
- 可以使用标准的 glob 模式匹配。
- 匹配模式最后跟反斜杠(/)说明要忽略的是目录。
- 要忽略指定模式以外的文件或目录,可以在模式前加上惊叹号(!)取反。
所谓的 glob 模式是指 shell 所使用的简化了的正则表达式。星号(*)匹配零个或多个任意字符;[abc] 匹配任何一个列在方括号中的字符(这个例子要么匹配一个 a,要么匹配一个 b,要么匹配一个 c);问号(?)只匹配一个任意字符;如果在方括号中使用短划线分隔两个字符,表示所有在这两个字符范围内的都可以匹配(比如 [0-9] 表示匹配所有 0 到 9 的数字)。
|
|
|
|
git diff对比的是工作目录和modified状态下文件的差异,git diff --cached对比的是staged状态文件和之前提交状态也就是工作目录下文件的差异。单单 git diff 不过是显示还没有暂存起来的改动,而不是这次工作和上次提交之间的差异。所以有时候你一下子暂存了所有更新过的文件后,运行 git diff 后却什么也没有,就是这个原因。提交时记录的是放在暂存区域的快照,任何还未暂存的仍然保持已修改状态,可以在下次提交时纳入版本管理。每一次运行提交操作,都是对你项目作一次快照,以后可以回到这个状态,或者进行比较。尽管使用暂存区域的方式可以精心准备要提交的细节,但有时候这么做略显繁琐。Git 提供了一个跳过使用暂存区域的方式,只要在提交的时候,给 git commit 加上 -a 选项,Git 就会自动把所有已经跟踪过的文件暂存起来一并提交,从而跳过 git add 步骤。
要从 Git 中移除某个文件,就必须要从已跟踪文件清单中移除(确切地说,是从暂存区域移除),然后提交。可以用 git rm 命令完成此项工作,并连带从工作目录中删除指定的文件,这样以后就不会出现在未跟踪文件清单中了。最后提交的时候,该文件就不再纳入版本管理了。如果删除之前修改过并且已经放到暂存区域的话,则必须要用强制删除选项-f(译注:即 force 的首字母),以防误删除文件后丢失修改的内容。另外一种情况是,我们想把文件从 Git 仓库中删除(亦即从暂存区域移除),但仍然希望保留在当前工作目录中。换句话说,仅是从跟踪清单中删除。比如一些大型日志文件或者一堆 .a 编译文件,不小心纳入仓库后,要移除跟踪但不删除文件,以便稍后在 .gitignore 文件中补上,用 --cached 选项即可:git rm --cached readme.txt。git rm \*~会递归删除当前目录及其子目录中所有 ~ 结尾的文件。因为 Git 有它自己的文件模式扩展匹配方式,所以我们不用 shell 来帮忙展开(译注:实际上不加反斜杠也可以运行,只不过按照 shell 扩展的话,仅仅删除指定目录下的文件而不会递归匹配。
运行 git mv 就相当于运行了下面三条命令:
|
|
git log 有许多选项可以帮助你搜寻感兴趣的提交,接下来我们介绍些最常用的。我们常用 -p 选项展开显示每次提交的内容差异,用 -2 则仅显示最近的两次更新。还有许多摘要选项可以用,比如 --stat,仅显示简要的增改行数统计。还有个常用的 --pretty 选项,可以指定使用完全不同于默认格式的方式展示提交历史。比如用 oneline 将每个提交放在一行显示,这在提交数很大时非常有用。另外还有 short,full 和 fuller 可以用,展示的信息或多或少有些不同。但最有意思的是 format,可以定制要显示的记录格式,这样的输出便于后期编程提取分析:
|
|
用 oneline 或 format 时结合 --graph 选项,可以看到开头多出一些 ASCII 字符串表示的简单图形,形象地展示了每个提交所在的分支及其分化衍合情况。git log --pretty=format:"%h %s" --graph。
|
|
有时候我们提交完了才发现漏掉了几个文件没有加,或者提交信息写错了。想要撤消刚才的提交操作,可以使用 --amend 选项重新提交:git commit --amend此命令将使用当前的暂存区域快照提交。如果刚才提交完没有作任何改动,直接运行此命令的话,相当于有机会重新编辑提交说明,但将要提交的文件快照和之前的一样。如果刚才提交时忘了暂存某些修改,可以先补上暂存操作,然后再运行 --amend 提交。
任何已经提交到 Git 的都可以被恢复。即便在已经删除的分支中的提交,或者用 --amend 重新改写的提交,都可以被恢复(关于数据恢复的内容见第九章)。所以,你可能失去的数据,仅限于没有提交过的,对 Git 来说它们就像从未存在过一样。
要查看当前配置有哪些远程仓库,可以用 git remote 命令,它会列出每个远程库的简短名字。在克隆完某个项目后,至少可以看到一个名为 origin 的远程库,Git 默认使用这个名字来标识你所克隆的原始仓库。
要添加一个新的远程仓库,可以指定一个简单的名字,以便将来引用,运行 git remote add [shortname] [url]
可以用下面的命令从远程仓库抓取数据到本地:git fetch [remote-name]。此命令会到远程仓库中拉取所有你本地仓库中还没有的数据。运行完成后,你就可以在本地访问该远程仓库中的所有分支,将其中某个分支合并到本地,或者只是取出某个分支,一探究竟。如果是克隆了一个仓库,此命令会自动将远程仓库归于 origin 名下。所以,git fetch origin 会抓取从你上次克隆以来别人上传到此远程仓库中的所有更新(或是上次 fetch 以来别人提交的更新)。有一点很重要,需要记住,fetch 命令只是将远端的数据拉到本地仓库,并不自动合并到当前工作分支,只有当你确实准备好了,才能手工合并。如果设置了某个分支用于跟踪某个远端仓库的分支,可以使用 git pull 命令自动抓取数据下来,然后将远端分支自动合并到本地仓库中当前分支。在日常工作中我们经常这么用,既快且好。实际上,默认情况下 git clone 命令本质上就是自动创建了本地的 master 分支用于跟踪远程仓库中的 master 分支(假设远程仓库确实有 master 分支)。所以一般我们运行 git pull,目的都是要从原始克隆的远端仓库中抓取数据后,合并到工作目录中的当前分支。
项目进行到一个阶段,要同别人分享目前的成果,可以将本地仓库中的数据推送到远程仓库。实现这个任务的命令很简单: git push [remote-name] [branch-name]。如果要把本地的 master 分支推送到 origin 服务器上(再次说明下,克隆操作会自动使用默认的 master 和 origin 名字),可以运行下面的命令:git push origin master,只有在所克隆的服务器上有写权限,或者同一时刻没有其他人在推数据,这条命令才会如期完成任务。如果在你推数据前,已经有其他人推送了若干更新,那你的推送操作就会被驳回。你必须先把他们的更新抓取到本地,合并到自己的项目中,然后才可以再次推送。
我们可以通过命令 git remote show [remote-name] 查看某个远程仓库的详细信息。
Git 中可以用 git remote rename 命令修改某个远程仓库在本地的简称,比如想把 pb 改成 paul,可以这么运行:git remote rename pb paul。
碰到远端仓库服务器迁移,或者原来的克隆镜像不再使用,又或者某个参与者不再贡献代码,那么需要移除对应的远端仓库,可以运行 git remote rm 命令:git remote rm pb。
列出现有标签的命令非常简单,直接运行 git tag 即可。Git 使用的标签有两种类型:轻量级的(lightweight)和含附注的(annotated)。轻量级标签就像是个不会变化的分支,实际上它就是个指向特定提交对象的引用。而含附注标签,实际上是存储在仓库中的一个独立对象,它有自身的校验和信息,包含着标签的名字,电子邮件地址和日期,以及标签说明,标签本身也允许使用 GNU Privacy Guard (GPG) 来签署或验证。一般我们都建议使用含附注型的标签,以便保留相关信息;当然,如果只是临时性加注标签,或者不需要旁注额外信息,用轻量级标签也没问题。
创建一个含附注类型的标签非常简单,用 -a (译注:取 annotated 的首字母)指定标签名字即可:git tag -a v1.4 -m 'my version 1.4',而 -m 选项则指定了对应的标签说明,Git 会将此说明一同保存在标签对象中。如果你有自己的私钥,还可以用 GPG 来签署标签,只需要把之前的 -a 改为 -s (译注: 取 signed 的首字母)即可。轻量级标签实际上就是一个保存着对应提交对象的校验和信息的文件。要创建这样的标签,一个 -a,-s 或 -m 选项都不用,直接给出标签名字即可:git tag v1.4-lw。可以使用 git tag -v [tag-name] (译注:取 verify 的首字母)的方式验证已经签署的标签。此命令会调用 GPG 来验证签名,所以你需要有签署者的公钥,存放在 keyring 中,才能验证。
默认情况下,git push 并不会把标签传送到远端服务器上,只有通过显式命令才能分享标签到远端仓库。其命令格式如同推送分支,运行 git push origin [tagname] 即可:git push origin v1.5。如果要一次推送所有本地新增的标签上去,可以使用 --tags 选项:git push origin --tags。
如果你用的是 Bash shell,可以试试看 Git 提供的自动补全脚本。下载 Git 的源代码,进入 contrib/completion 目录,会看到一个 git-completion.bash 文件。source ~/.git-completion.bash
|
|
Git 分支
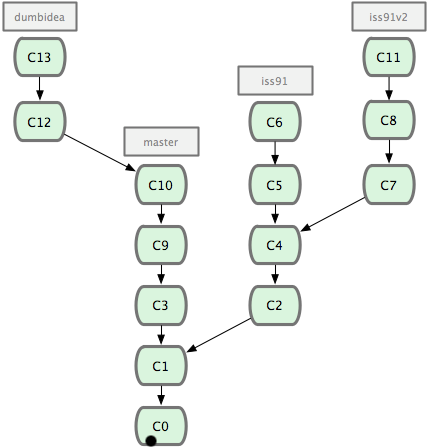
在 Git 中提交时,会保存一个提交(commit)对象,该对象包含一个指向暂存内容快照的指针,包含本次提交的作者等相关附属信息,包含零个或多个指向该提交对象的父对象指针:首次提交是没有直接祖先的,普通提交有一个祖先,由两个或多个分支合并产生的提交则有多个祖先。
为直观起见,我们假设在工作目录中有三个文件,准备将它们暂存后提交。暂存操作会对每一个文件计算校验和(即第一章中提到的 SHA-1 哈希字串),然后把当前版本的文件快照保存到 Git 仓库中(Git 使用 blob 类型的对象存储这些快照),并将校验和加入暂存区域。当使用 git commit 新建一个提交对象前,Git 会先计算每一个子目录(本例中就是项目根目录)的校验和,然后在 Git 仓库中将这些目录保存为树(tree)对象。之后 Git 创建的提交对象,除了包含相关提交信息以外,还包含着指向这个树对象(项目根目录)的指针,如此它就可以在将来需要的时候,重现此次快照的内容了。Git 仓库中有五个对象:三个表示文件快照内容的 blob 对象;一个记录着目录树内容及其中各个文件对应 blob 对象索引的 tree 对象;以及一个包含指向 tree 对象(根目录)的索引和其他提交信息元数据的 commit 对象。
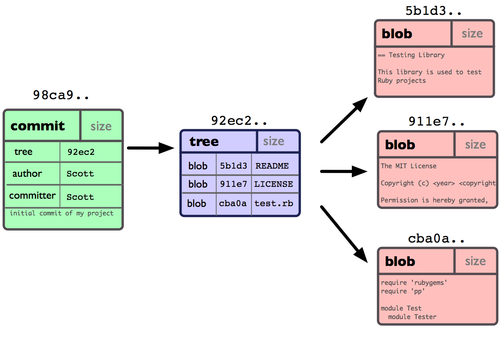
作些修改后再次提交,那么这次的提交对象会包含一个指向上次提交对象的指针(译注:即下图中的 parent 对象)。
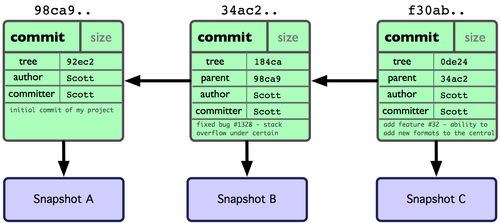
Git 中的分支,其实本质上仅仅是个指向 commit 对象的可变指针。Git 会使用 master 作为分支的默认名字。在若干次提交后,你其实已经有了一个指向最后一次提交对象的 master 分支,它在每次提交的时候都会自动向前移动。分支其实就是从某个提交对象往回看的历史。
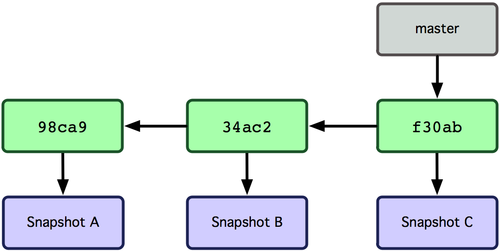
Git 又是如何创建一个新的分支的呢?答案很简单,创建一个新的分支指针。比如新建一个 testing 分支,可以使用 git branch 命令:git branch testing。这会在当前 commit 对象上新建一个分支指针。
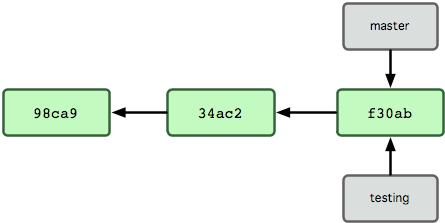
Git 是如何知道你当前在哪个分支上工作的呢?其实答案也很简单,它保存着一个名为 HEAD 的特别指针。在 Git 中,它是一个指向你正在工作中的本地分支的指针(译注:将 HEAD 想象为当前分支的别名。)。运行 git branch 命令,仅仅是建立了一个新的分支,但不会自动切换到这个分支中去,所以在这个例子中,我们依然还在 master 分支里工作。
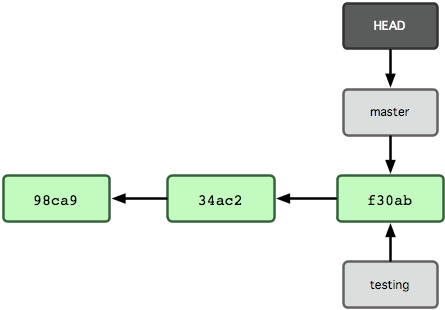
要切换到其他分支,可以执行 git checkout 命令。git checkout testing,这样 HEAD 就指向了 testing 分支。
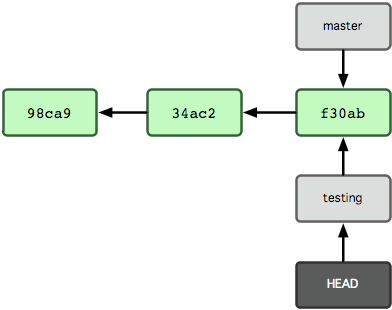
由于 Git 中的分支实际上仅是一个包含所指对象校验和(40 个字符长度 SHA-1 字串)的文件,所以创建和销毁一个分支就变得非常廉价。说白了,新建一个分支就是向一个文件写入 41 个字节(外加一个换行符)那么简单,当然也就很快了。
git branch -d hotfix删除hotfix分支。
在解决了所有文件里的所有冲突后,运行 git add 将把它们标记为已解决状态(译注:实际上就是来一次快照保存到暂存区域。)。因为一旦暂存,就表示冲突已经解决。如果你想用一个有图形界面的工具来解决这些问题,不妨运行 git mergetool,它会调用一个可视化的合并工具并引导你解决所有冲突:git mergetool。退出合并工具以后,Git 会询问你合并是否成功。如果回答是,它会为你把相关文件暂存起来,以表明状态为已解决。如果觉得满意了,并且确认所有冲突都已解决,也就是进入了暂存区,就可以用 git commit 来完成这次合并提交。
git branch 命令不仅仅能创建和删除分支,如果不加任何参数,它会给出当前所有分支的清单。若要查看各个分支最后一个提交对象的信息,运行 git branch -v。要从该清单中筛选出你已经(或尚未)与当前分支合并的分支,可以用 --merge 和 --no-merged 选项。比如用 git branch --merge 查看哪些分支已被并入当前分支(译注:也就是说哪些分支是当前分支的直接上游。)可以用 git branch --no-merged 查看尚未合并的工作。它会显示还未合并进来的分支。由于这些分支中还包含着尚未合并进来的工作成果,所以简单地用 git branch -d 删除该分支会提示错误,因为那样做会丢失数据。
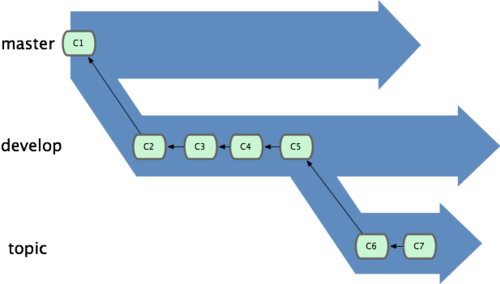
远程分支(remote branch)是对远程仓库中的分支的索引。它们是一些无法移动的本地分支;只有在 Git 进行网络交互时才会更新。远程分支就像是书签,提醒着你上次连接远程仓库时上面各分支的位置。
一次 Git 克隆会建立你自己的本地分支 master 和远程分支 origin/master,并且将它们都指向 origin 上的 master 分支。如果你在本地 master 分支做了些改动,与此同时,其他人向 git.ourcompany.com 推送了他们的更新,那么服务器上的 master 分支就会向前推进,而于此同时,你在本地的提交历史正朝向不同方向发展。不过只要你不和服务器通讯,你的 origin/master 指针仍然保持原位不会移动。可以运行 git fetch origin 来同步远程服务器上的数据到本地。该命令首先找到 origin 是哪个服务器(本例为 git.ourcompany.com),从上面获取你尚未拥有的数据,更新你本地的数据库,然后把 origin/master 的指针移到它最新的位置上。要想和其他人分享某个本地分支,你需要把它推送到一个你拥有写权限的远程仓库。你创建的本地分支不会因为你的写入操作而被自动同步到你引入的远程服务器上,你需要明确地执行推送分支的操作。换句话说,对于无意分享的分支,你尽管保留为私人分支好了,而只推送那些协同工作要用到的特性分支。如果你有个叫 serverfix 的分支需要和他人一起开发,可以运行 git push (远程仓库名) (分支名):git push origin serverfix。这里其实走了一点捷径。Git 自动把 serverfix 分支名扩展为 refs/heads/serverfix:refs/heads/serverfix,意为“取出我在本地的 serverfix 分支,推送到远程仓库的 serverfix 分支中去”。也可以运行 git push origin serverfix:serverfix 来实现相同的效果,它的意思是“上传我本地的 serverfix 分支到远程仓库中去,仍旧称它为 serverfix 分支”。通过此语法,你可以把本地分支推送到某个命名不同的远程分支:若想把远程分支叫作 awesomebranch,可以用 git push origin serverfix:awesomebranch 来推送数据。值得注意的是,在 fetch 操作下载好新的远程分支之后,你仍然无法在本地编辑该远程仓库中的分支。换句话说,在本例中,你不会有一个新的 serverfix 分支,有的只是一个你无法移动的 origin/serverfix 指针。如果要把该远程分支的内容合并到当前分支,可以运行 git merge origin/serverfix。如果想要一份自己的 serverfix 来开发,可以在远程分支的基础上分化出一个新的分支来:git checkout -b serverfix origin/serverfix。这会切换到新建的 serverfix 本地分支,其内容同远程分支 origin/serverfix 一致,这样你就可以在里面继续开发了。从远程分支 checkout 出来的本地分支,称为 跟踪分支 (tracking branch)。跟踪分支是一种和某个远程分支有直接联系的本地分支。在跟踪分支里输入 git push,Git 会自行推断应该向哪个服务器的哪个分支推送数据。同样,在这些分支里运行 git pull 会获取所有远程索引,并把它们的数据都合并到本地分支中来。在克隆仓库时,Git 通常会自动创建一个名为 master 的分支来跟踪 origin/master。这正是 git push 和 git pull 一开始就能正常工作的原因。当然,你可以随心所欲地设定为其它跟踪分支,比如 origin 上除了 master 之外的其它分支。刚才我们已经看到了这样的一个例子:git checkout -b [分支名] [远程名]/[分支名]。如果你有 1.6.2 以上版本的 Git,还可以用 --track 选项简化:git checkout --track origin/serverfix。要为本地分支设定不同于远程分支的名字,只需在第一个版本的命令里换个名字:git checkout -b sf origin/serverfix。如果不再需要某个远程分支了,比如搞定了某个特性并把它合并进了远程的 master 分支(或任何其他存放稳定代码的分支),可以用这个非常无厘头的语法来删除它:git push [远程名] :[分支名]。如果想在服务器上删除 serverfix 分支,运行下面的命令:git push origin :serverfix。有种方便记忆这条命令的方法:记住我们不久前见过的 git push [远程名] [本地分支]:[远程分支] 语法,如果省略 [本地分支],那就等于是在说“在这里提取空白然后把它变成[远程分支]”。
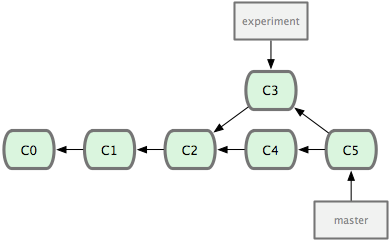
把一个分支中的修改整合到另一个分支的办法有两种:merge 和 rebase。最容易的整合分支的方法是 merge 命令,它会把两个分支最新的快照(C3 和 C4)以及二者最新的共同祖先(C2)进行三方合并,合并的结果是产生一个新的提交对象(C5)。
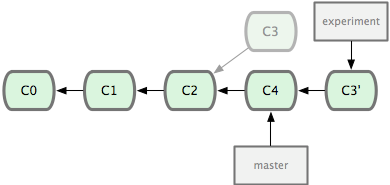
其实,还有另外一个选择:你可以把在 C3 里产生的变化补丁在 C4 的基础上重新打一遍。在 Git 里,这种操作叫做衍合(rebase)。有了 rebase 命令,就可以把在一个分支里提交的改变移到另一个分支里重放一遍。
|
|
它的原理是回到两个分支最近的共同祖先,根据当前分支(也就是要进行衍合的分支 experiment)后续的历次提交对象(这里只有一个 C3),生成一系列文件补丁,然后以基底分支(也就是主干分支 master)最后一个提交对象(C4)为新的出发点,逐个应用之前准备好的补丁文件,最后会生成一个新的合并提交对象(C3’),从而改写 experiment 的提交历史,使它成为 master 分支的直接下游。
现在回到 master 分支,进行一次快进合并。
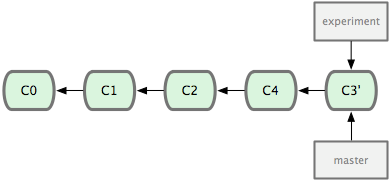
现在的 C3’ 对应的快照,其实和普通的三方合并,即上个例子中的 C5 对应的快照内容一模一样了。虽然最后整合得到的结果没有任何区别,但衍合能产生一个更为整洁的提交历史。如果视察一个衍合过的分支的历史记录,看起来会更清楚:仿佛所有修改都是在一根线上先后进行的,尽管实际上它们原本是同时并行发生的。一般我们使用衍合的目的,是想要得到一个能在远程分支上干净应用的补丁 — 比如某些项目你不是维护者,但想帮点忙的话,最好用衍合:先在自己的一个分支里进行开发,当准备向主项目提交补丁的时候,根据最新的 origin/master 进行一次衍合操作然后再提交,这样维护者就不需要做任何整合工作(译注:实际上是把解决分支补丁同最新主干代码之间冲突的责任,化转为由提交补丁的人来解决。),只需根据你提供的仓库地址作一次快进合并,或者直接采纳你提交的补丁。合并结果中最后一次提交所指向的快照,无论是通过衍合,还是三方合并,都会得到相同的快照内容,只不过提交历史不同罢了。衍合是按照每行的修改次序重演一遍修改,而合并是把最终结果合在一起。
如果把衍合当成一种在推送之前清理提交历史的手段,而且仅仅衍合那些尚未公开的提交对象,就没问题。如果衍合那些已经公开的提交对象,并且已经有人基于这些提交对象开展了后续开发工作的话,就会出现叫人沮丧的麻烦。
服务器上的 Git
分布式 Git
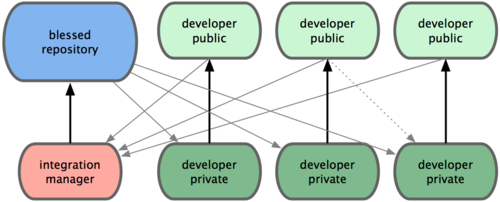
集中管理员工作流:由于 Git 允许使用多个远程仓库,开发者便可以建立自己的公共仓库,往里面写数据并共享给他人,而同时又可以从别人的仓库中提取他们的更新过来。这种情形通常都会有个代表着官方发布的项目仓库(blessed repository),开发者们由此仓库克隆出一个自己的公共仓库(developer public),然后将自己的提交推送上去,请求官方仓库的维护者拉取更新合并到主项目。维护者在自己的本地也有个克隆仓库(integration manager),他可以将你的公共仓库作为远程仓库添加进来,经过测试无误后合并到主干分支,然后再推送到官方仓库。
- 项目维护者可以推送数据到公共仓库 blessed repository。
- 贡献者克隆此仓库,修订或编写新代码。
- 贡献者推送数据到自己的公共仓库 developer public。
- 贡献者给维护者发送邮件,请求拉取自己的最新修订。
- 维护者在自己本地的 integration manger 仓库中,将贡献者的仓库加为远程仓库,合并更新并做测试。
- 维护者将合并后的更新推送到主仓库 blessed repository。
在 GitHub 网站上使用得最多的就是这种工作流。人们可以复制(fork 亦即克隆)某个项目到自己的列表中,成为自己的公共仓库。随后将自己的更新提交到这个仓库,所有人都可以看到你的每次更新。这么做最主要的优点在于,你可以按照自己的节奏继续工作,而不必等待维护者处理你提交的更新;而维护者也可以按照自己的节奏,任何时候都可以过来处理接纳你的贡献。
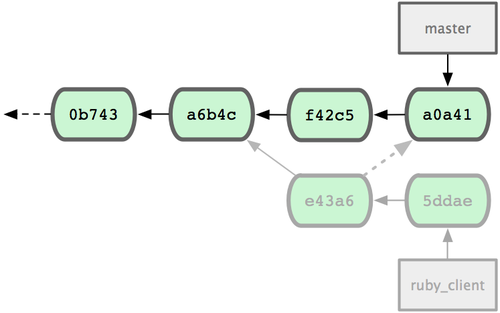
cherry-pick挑拣类似于针对某次特定提交的衍合。它首先提取某次提交的补丁,然后试着应用在当前分支上。如果某个特性分支上有多个commits,但你只想引入其中之一就可以使用这种方法。
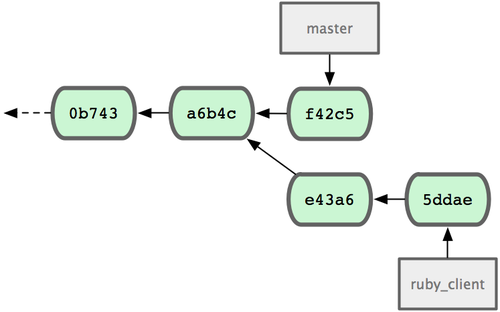
如果你希望拉取e43a6到你的主干分支,可以这样:git cherry-pick e43a6fd3e94888d76779ad79fb568ed180e5fcdf。这将会引入e43a6的代码,但是会得到不同的SHA-1值,因为应用日期不同。
Git 工具
Git 可以为你的 SHA-1 值生成出简短且唯一的缩写。如果你传递 –abbrev-commit 给 git log 命令,输出结果里就会使用简短且唯一的值;它默认使用七个字符来表示,不过必要时为了避免 SHA-1 的歧义,会增加字符数:git log --abbrev-commit --pretty=oneline
如果你想知道某个分支指向哪个特定的 SHA,或者想看任何一个例子中被简写的 SHA-1,你可以使用一个叫做 rev-parse 的 Git 探测工具。git rev-parse topic1。
在你工作的同时,Git 在后台的工作之一就是保存一份引用日志——一份记录最近几个月你的 HEAD 和分支引用的日志。你可以使用 git reflog 来查看引用日志。
|
|
每次你的分支顶端因为某些原因被修改时,Git 就会为你将信息保存在这个临时历史记录里面。你也可以使用这份数据来指明更早的分支。如果你想查看仓库中 HEAD 在五次前的值,你可以使用引用日志的输出中的 @{n} 引用:git show HEAD@{5}。你也可以使用这个语法来查看某个分支在一定时间前的位置。例如,想看你的 master 分支昨天在哪,你可以输入git show master@{yesterday},它就会显示昨天分支的顶端在哪。这项技术只对还在你引用日志里的数据有用,所以不能用来查看比几个月前还早的提交。想要看类似于 git log 输出格式的引用日志信息,你可以运行 git log -g。
引用日志信息只存在于本地——这是一个记录你在你自己的仓库里做过什么的日志。其他人拷贝的仓库里的引用日志不会和你的相同;而你新克隆一个仓库的时候,引用日志是空的,因为你在仓库里还没有操作。git show HEAD@{2.months.ago} 这条命令只有在你克隆了一个项目至少两个月时才会有用——如果你是五分钟前克隆的仓库,那么它将不会有结果返回。
另一种指明某次提交的常用方法是通过它的祖先。如果你在引用最后加上一个 ^,Git 将其理解为此次提交的父提交。 想看上一次提交,你可以使用 HEAD^,意思是“HEAD 的父提交”:git show HEAD^。你也可以在 ^ 后添加一个数字——例如,d921970^2 意思是“d921970 的第二父提交”。这种语法只在合并提交时有用,因为合并提交可能有多个父提交。第一父提交是你合并时所在分支,而第二父提交是你所合并的分支。另外一个指明祖先提交的方法是 ~。这也是指向第一父提交,所以 HEAD~ 和 HEAD^ 是等价的。当你指定数字的时候就明显不一样了。HEAD~2 是指“第一父提交的第一父提交”,也就是“祖父提交”——它会根据你指定的次数检索第一父提交。你也可以混合使用这些语法——你可以通过 HEAD~3^2 指明先前引用的第二父提交(假设它是一个合并提交)。
最常用的指明范围的方法是双点的语法。这种语法主要是让 Git 区分出可从一个分支中获得而不能从另一个分支中获得的提交。你想要查看你的试验分支上哪些没有被提交到主分支,那么你就可以使用 master..experiment 来让 Git 显示这些提交的日志——这句话的意思是“所有可从experiment分支中获得而不能从master分支中获得的提交”。另一方面,如果你想看相反的——所有在 master 而不在 experiment 中的分支——你可以交换分支的名字。experiment..master 显示所有可在 master 获得而在 experiment 中不能的提交:git log experiment..master。这个语法的另一种常见用途是查看你将把什么推送到远程:git log origin/master..HEAD。你也可以留空语法中的一边来让 Git 来假定它是 HEAD。例如,输入 git log origin/master.. 将得到和上面的例子一样的结果—— Git 使用 HEAD 来代替不存在的一边。
双点语法就像速记一样有用;但是你也许会想针对两个以上的分支来指明修订版本,比如查看哪些提交被包含在某些分支中的一个,但是不在你当前的分支上。Git允许你在引用前使用^字符或者–not指明你不希望提交被包含其中的分支。因此下面三个命令是等同的:
|
|
这样很好,因为它允许你在查询中指定多于两个的引用,而这是双点语法所做不到的。例如,如果你想查找所有从refA或refB包含的但是不被refC包含的提交,你可以输入下面中的一个git log refA refB ^refC或者git log refA refB --not refC。
最后一种主要的范围选择语法是三点语法,这个可以指定被两个引用中的一个包含但又不被两者同时包含的分支。如果你想查看master或者experiment中包含的但不是两者共有的引用,你可以运行git log master...experiment。这种情形下,log命令的一个常用参数是–left-right,它会显示每个提交到底处于哪一侧的分支。这使得数据更加有用。
|
|
Git提供了很多脚本来辅助某些命令行任务。这里,你将看到一些交互式命令,它们帮助你方便地构建只包含特定组合和部分文件的提交。在你修改了一大批文件然后决定将这些变更分布在几个各有侧重的提交而不是单个又大又乱的提交时,这些工具非常有用。用这种方法,你可以确保你的提交在逻辑上划分为相应的变更集,以便于供和你一起工作的开发者审阅。如果你运行git add时加上-i或者--interactive选项,Git就进入了一个交互式的shell模式,显示一些类似于下面的信息:
|
|
经常有这样的事情发生,当你正在进行项目中某一部分的工作,里面的东西处于一个比较杂乱的状态,而你想转到其他分支上进行一些工作。问题是,你不想提交进行了一半的工作,否则以后你无法回到这个工作点。解决这个问题的办法就是git stash命令。“‘储藏”“可以获取你工作目录的中间状态——也就是你修改过的被追踪的文件和暂存的变更——并将它保存到一个未完结变更的堆栈中,随时可以重新应用。想切换分支,但是你还不想提交你正在进行中的工作;所以你储藏这些变更。为了往堆栈推送一个新的储藏,只要运行 git stash,你的工作目录就干净了。这时,你可以方便地切换到其他分支工作;你的变更都保存在栈上。要查看现有的储藏,你可以使用 git stash list。你可以重新应用你刚刚实施的储藏,所采用的命令就是之前在原始的 stash 命令的帮助输出里提示的:git stash apply。如果你想应用更早的储藏,你可以通过名字指定它,像这样:git stash apply stash@{2}。如果你不指明,Git 默认使用最近的储藏并尝试应用它:
你可以看到 Git 重新修改了你所储藏的那些当时尚未提交的文件。在这个案例里,你尝试应用储藏的工作目录是干净的,并且属于同一分支;但是一个干净的工作目录和应用到相同的分支上并不是应用储藏的必要条件。你可以在其中一个分支上保留一份储藏,随后切换到另外一个分支,再重新应用这些变更。在工作目录里包含已修改和未提交的文件时,你也可以应用储藏——Git 会给出归并冲突如果有任何变更无法干净地被应用。对文件的变更被重新应用,但是被暂存的文件没有重新被暂存。想那样的话,你必须在运行 git stash apply 命令时带上一个--index 的选项来告诉命令重新应用被暂存的变更。如果你是这么做的,你应该已经回到你原来的位置。
apply 选项只尝试应用储藏的工作——储藏的内容仍然在栈上。要移除它,你可以运行 git stash drop,加上你希望移除的储藏的名字,你也可以运行 git stash pop 来重新应用储藏,同时立刻将其从堆栈中移走。
|
|
在某些情况下,你可能想应用储藏的修改,在进行了一些其他的修改后,又要取消之前所应用储藏的修改。Git没有提供类似于 stash unapply 的命令,但是可以通过取消该储藏的补丁达到同样的效果:git stash show -p stash@{0} | git apply -R。同样的,如果你沒有指定具体的某个储藏,Git 会选择最近的储藏:git stash show -p | git apply -R。git config --global alias.stash-unapply '!git stash show -p | git apply -R'
如果你储藏了一些工作,暂时不去理会,然后继续在你储藏工作的分支上工作,你在重新应用工作时可能会碰到一些问题。如果尝试应用的变更是针对一个你那之后修改过的文件,你会碰到一个归并冲突并且必须去化解它。如果你想用更方便的方法来重新检验你储藏的变更,你可以运行 git stash branch,这会创建一个新的分支,检出你储藏工作时的所处的提交,重新应用你的工作,如果成功,将会丢弃储藏。
很多时候,在 Git 上工作的时候,你也许会由于某种原因想要修订你的提交历史。Git 的一个卓越之处就是它允许你在最后可能的时刻再作决定。你可以在你即将提交暂存区时决定什么文件归入哪一次提交,你可以使用 stash 命令来决定你暂时搁置的工作,你可以重写已经发生的提交以使它们看起来是另外一种样子。这个包括改变提交的次序、改变说明或者修改提交中包含的文件,将提交归并、拆分或者完全删除——这一切在你尚未开始将你的工作和别人共享前都是可以的。
改变最近一次提交也许是最常见的重写历史的行为。对于你的最近一次提交,你经常想做两件基本事情:改变提交说明,或者改变你刚刚通过增加,改变,删除而记录的快照。
如果你只想修改最近一次提交说明,这非常简单:git commit --amend。这会把你带入文本编辑器,里面包含了你最近一次提交说明,供你修改。当你保存并退出编辑器,这个编辑器会写入一个新的提交,里面包含了那个说明,并且让它成为你的新的最近一次提交。如果你完成提交后又想修改被提交的快照,增加或者修改其中的文件,可能因为你最初提交时,忘了添加一个新建的文件,这个过程基本上一样。你通过修改文件然后对其运行git add或对一个已被记录的文件运行git rm,随后的git commit --amend会获取你当前的暂存区并将它作为新提交对应的快照。使用这项技术的时候你必须小心,因为修正会改变提交的SHA-1值。这个很像是一次非常小的rebase——不要在你最近一次提交被推送后还去修正它。
要修改历史中更早的提交,你必须采用更复杂的工具。Git没有一个修改历史的工具,但是你可以使用rebase工具来衍合一系列的提交到它们原来所在的HEAD上而不是移到新的上。依靠这个交互式的rebase工具,你就可以停留在每一次提交后,如果你想修改或改变说明、增加文件或任何其他事情。你可以通过给git rebase增加-i选项来以交互方式地运行rebase。你必须通过告诉命令衍合到哪次提交,来指明你需要重写的提交的回溯深度。
你想修改最近三次的提交说明,或者其中任意一次,你必须给git rebase -i提供一个参数,指明你想要修改的提交的父提交,例如HEAD~2或者HEAD~3。可能记住~3更加容易,因为你想修改最近三次提交;但是请记住你事实上所指的是四次提交之前,即你想修改的提交的父提交。git rebase -i HEAD~3这是一个衍合命令——HEAD~3..HEAD范围内的每一次提交都会被重写,无论你是否修改说明。不要涵盖你已经推送到中心服务器的提交——这么做会使其他开发者产生混乱,因为你提供了同样变更的不同版本。交互式的rebase给了你一个即将运行的脚本。它会从你在命令行上指明的提交开始(HEAD~3)然后自上至下重播每次提交里引入的变更。它将最早的列在顶上而不是最近的,因为这是第一个需要重播的。
交互式的衍合工具还可以将一系列提交压制为单一提交。
拆分提交就是撤销一次提交,然后多次部分地暂存或提交直到结束。你可以在rebase -i脚本中修改你想拆分的提交前的指令为"edit"。
如果你想用脚本的方式修改大量的提交,还有一个重写历史的选项可以用——例如,全局性地修改电子邮件地址或者将一个文件从所有提交中删除。这个命令是filter-branch,这个会大面积地修改你的历史,所以你很有可能不该去用它,除非你的项目尚未公开,没有其他人在你准备修改的提交的基础上工作。尽管如此,这个可以非常有用。你会学习一些常见用法,借此对它的能力有所认识。
从所有提交中删除一个文件,这个经常发生。有些人不经思考使用git add .,意外地提交了一个巨大的二进制文件,你想将它从所有地方删除。也许你不小心提交了一个包含密码的文件,而你想让你的项目开源。filter-branch大概会是你用来清理整个历史的工具。要从整个历史中删除一个名叫password.txt的文件,你可以在filter-branch上使用--tree-filter选项:git filter-branch --tree-filter 'rm -f passwords.txt' HEAD。--tree-filter选项会在每次检出项目时先执行指定的命令然后重新提交结果。在这个例子中,你会在所有快照中删除一个名叫 password.txt 的文件,无论它是否存在。如果你想删除所有不小心提交上去的编辑器备份文件,你可以运行类似git filter-branch --tree-filter 'rm -f *~' HEAD的命令。你可以观察到 Git 重写目录树并且提交,然后将分支指针移到末尾。一个比较好的办法是在一个测试分支上做这些然后在你确定产物真的是你所要的之后,再 hard-reset 你的主分支。要在你所有的分支上运行filter-branch的话,你可以传递一个–all给命令。
假设你完成了从另外一个代码控制系统的导入工作,得到了一些没有意义的子目录(trunk, tags等等)。如果你想让trunk子目录成为每一次提交的新的项目根目录,filter-branch也可以帮你做到:git filter-branch --subdirectory-filter trunk HEAD。
另一个常见的案例是你在开始时忘了运行git config来设置你的姓名和电子邮件地址,也许你想开源一个项目,把你所有的工作电子邮件地址修改为个人地址。无论哪种情况你都可以用filter-branch来更换多次提交里的电子邮件地址。你必须小心一些,只改变属于你的电子邮件地址,所以你使用–commit-filter:
|
|
这个会遍历并重写所有提交使之拥有你的新地址。因为提交里包含了它们的父提交的SHA-1值,这个命令会修改你的历史中的所有提交,而不仅仅是包含了匹配的电子邮件地址的那些。
如果你在追踪代码中的缺陷想知道这是什么时候为什么被引进来的,文件标注会是你的最佳工具。它会显示文件中对每一行进行修改的最近一次提交。因此,如果你发现自己代码中的一个方法存在缺陷,你可以用git blame来标注文件,查看那个方法的每一行分别是由谁在哪一天修改的。下面这个例子使用了-L选项来限制输出范围在第12至22行:git blame -L 12,22 simplegit.rb
另一件很酷的事情是在 Git 中你不需要显式地记录文件的重命名。它会记录快照然后根据现实尝试找出隐式的重命名动作。这其中有一个很有意思的特性就是你可以让它找出所有的代码移动。如果你在git blame后加上-C,Git会分析你在标注的文件然后尝试找出其中代码片段的原始出处,如果它是从其他地方拷贝过来的话。最近,我在将一个名叫GITServerHandler.m的文件分解到多个文件中,其中一个是GITPackUpload.m。通过对GITPackUpload.m执行带-C参数的blame命令,我可以看到代码块的原始出处:
|
|
这真的非常有用。通常,你会把你拷贝代码的那次提交作为原始提交,因为这是你在这个文件中第一次接触到那几行。Git可以告诉你编写那些行的原始提交,即便是在另一个文件里。
标注文件在你知道问题是哪里引入的时候会有帮助。如果你不知道,并且自上次代码可用的状态已经经历了上百次的提交,你可能就要求助于bisect命令了。bisect会在你的提交历史中进行二分查找来尽快地确定哪一次提交引入了错误。
例如你刚刚推送了一个代码发布版本到产品环境中,对代码为什么会表现成那样百思不得其解。你回到你的代码中,还好你可以重现那个问题,但是找不到在哪里。你可以对代码执行bisect来寻找。首先你运行git bisect start启动,然后你用git bisect bad来告诉系统当前的提交已经有问题了。然后你必须告诉bisect已知的最后一次正常状态是哪次提交,使用git bisect good [good_commit]:
|
|
Git 发现在你标记为正常的提交(v1.0)和当前的错误版本之间有大约12次提交,于是它检出中间的一个。在这里,你可以运行测试来检查问题是否存在于这次提交。如果是,那么它是在这个中间提交之前的某一次引入的;如果否,那么问题是在中间提交之后引入的。假设这里是没有错误的,那么你就通过git bisect good来告诉 Git 然后继续你的旅程:git bisect good。现在你在另外一个提交上了,在你刚刚测试通过的和一个错误提交的中点处。你再次运行测试然后发现这次提交是错误的,因此你通过git bisect bad来告诉Git:git bisect bad。当你完成之后,你应该运行git bisect reset来重设你的HEAD到你开始前的地方,否则你会处于一个诡异的地方:git bisect reset。这是个强大的工具,可以帮助你检查上百的提交,在几分钟内找出缺陷引入的位置。事实上,如果你有一个脚本会在工程正常时返回0,错误时返回非0的话,你可以完全自动地执行git bisect。首先你需要提供已知的错误和正确提交来告诉它二分查找的范围。你可以通过bisect start命令来列出它们,先列出已知的错误提交再列出已知的正确提交:git bisect start HEAD v1.0。
经常有这样的事情,当你在一个项目上工作时,你需要在其中使用另外一个项目。也许它是一个第三方开发的库或者是你独立开发和并在多个父项目中使用的。这个场景下一个常见的问题产生了:你想将两个项目单独处理但是又需要在其中一个中使用另外一个。Git 通过子模块处理这个问题。子模块允许你将一个 Git 仓库当作另外一个Git仓库的子目录。这允许你克隆另外一个仓库到你的项目中并且保持你的提交相对独立。把外部的仓库克隆到你的子目录中。你通过git submodule add将外部项目加为子模块:git submodule add git://github.com/chneukirchen/rack.git rack,注意到有一个.gitmodules文件。这是一个配置文件,保存了项目 URL 和你拉取到的本地子目录
|
|
很重要的一点是这个文件.gitmodules跟其他文件一样也是处于版本控制之下的,就像你的.gitignore文件一样。它跟项目里的其他文件一样可以被推送和拉取。这是其他克隆此项目的人获知子模块项目来源的途径。
尽管rack是你工作目录里的子目录,但 Git 把它视作一个子模块,当你不在那个目录里时并不记录它的内容。取而代之的是,Git 将它记录成来自那个仓库的一个特殊的提交。当你在那个子目录里修改并提交时,子项目会通知那里的 HEAD 已经发生变更并记录你当前正在工作的那个提交;通过那样的方法,当其他人克隆此项目,他们可以重新创建一致的环境。这是关于子模块的重要一点:你记录他们当前确切所处的提交。你不能记录一个子模块的master或者其他的符号引用。
当你提交时,会看到类似下面的:
|
|
注意 rack 条目的 160000 模式。这在Git中是一个特殊模式,基本意思是你将一个提交记录为一个目录项而不是子目录或者文件。你可以将rack目录当作一个独立的项目,保持一个指向子目录的最新提交的指针然后反复地更新上层项目。所有的Git命令都在两个子目录里独立工作。
克隆一个带子模块的项目。当你接收到这样一个项目,你将得到了包含子项目的目录,但里面没有文件,rack目录存在了,但是是空的。你必须运行两个命令:git submodule init来初始化你的本地配置文件,git submodule update来从那个项目拉取所有数据并检出你上层项目里所列的合适的提交。现在你的rack子目录就处于你先前提交的确切状态了。如果另外一个开发者变更了 rack 的代码并提交,你拉取那个引用然后归并之,将得到稍有点怪异的东西:你归并来的仅仅上是一个指向你的子模块的指针;但是它并不更新你子模块目录里的代码,所以看起来你的工作目录处于一个临时状态:事情就是这样,因为你所拥有的指向子模块的指针和子模块目录的真实状态并不匹配。为了修复这一点,你必须再次运行git submodule update。每次你从主项目中拉取一个子模块的变更都必须这样做。看起来很怪但是管用。
子树归并的思想是你拥有两个工程,其中一个项目映射到另外一个项目的子目录中,反过来也一样。当你指定一个子树归并,Git可以聪明地探知其中一个是另外一个的子树从而实现正确的归并——这相当神奇。首先你将 Rack 应用加入到项目中。你将 Rack 项目当作你项目中的一个远程引用,然后将它检出到它自身的分支:
|
|
现在在你的rack_branch分支中就有了Rack项目的根目录,而你自己的项目在master分支中。如果你先检出其中一个然后另外一个,你会看到它们有不同的项目根目录:
|
|
要将 Rack 项目当作子目录拉取到你的master项目中。你可以在 Git 中用git read-tree来实现。git read-tree --prefix=rack/ -u rack_branch
当你提交的时候,看起来就像你在那个子目录下拥有Rack的文件——就像你从一个tarball里拷贝的一样。有意思的是你可以比较容易地归并其中一个分支的变更到另外一个。因此,如果 Rack 项目更新了,你可以通过切换到那个分支并执行拉取来获得上游的变更:
|
|
然后,你可以将那些变更归并回你的 master 分支。你可以使用git merge -s subtree,它会工作的很好;但是 Git 同时会把历史归并到一起,这可能不是你想要的。为了拉取变更并预置提交说明,需要在-s subtree策略选项的同时使用--squash和--no-commit选项。
|
|
所有 Rack 项目的变更都被归并可以进行本地提交。你也可以做相反的事情——在你主分支的rack目录里进行变更然后归并回rack_branch分支,然后将它们提交给维护者或者推送到上游。为了得到rack子目录和你rack_branch分支的区别——以决定你是否需要归并它们——你不能使用一般的diff命令。而是对你想比较的分支运行git diff-tree:git diff-tree -p rack_branch,或者,为了比较你的rack子目录和服务器上你拉取时的master分支,你可以运行git diff-tree -p rack_remote/master。
自定义 Git
Git 使用一系列的配置文件来存储你定义的偏好,它首先会查找/etc/gitconfig文件,该文件含有 对系统上所有用户及他们所拥有的仓库都生效的配置值(译注:gitconfig是全局配置文件), 如果传递--system选项给git config命令, Git 会读写这个文件。接下来 Git 会查找每个用户的~/.gitconfig文件,你能传递--global选项让 Git读写该文件。最后 Git 会查找由用户定义的各个库中 Git 目录下的配置文件(.git/config),该文件中的值只对属主库有效。 以上阐述的三层配置从一般到特殊层层推进,如果定义的值有冲突,以后面层中定义的为准,例如:在.git/config和/etc/gitconfig的较量中, .git/config取得了胜利。虽然你也可以直接手动编辑这些配置文件,但是运行git config命令将会来得简单些。
commit.template如果把此项指定为你系统上的一个文件,当你提交的时候, Git 会默认使用该文件定义的内容。 例如:你创建了一个模板文件$HOME/.gitmessage.txt,它看起来像这样:
|
|
设置commit.template,当运行git commit时, Git 会在你的编辑器中显示以上的内容, 设置commit.template如下:git config --global commit.template $HOME/.gitmessage.txt
core.pager指定 Git 运行诸如log、diff等所使用的分页器,你能设置成用more或者任何你喜欢的分页器(默认用的是less), 当然你也可以什么都不用,设置空字符串git config --global core.pager ''
user.signingkey如果你要创建经签署的含附注的标签,那么把你的GPG签署密钥设置为配置项会更好,设置密钥ID如下:git config --global user.signingkey <gpg-key-id>,现在你能够签署标签,从而不必每次运行git tag命令时定义密钥:git tag -s <tag-name>。
core.excludesfile能在项目库的.gitignore文件里头用模式来定义那些无需纳入 Git 管理的文件,这样它们不会出现在未跟踪列表, 也不会在你运行git add后被暂存。然而,如果你想用项目库之外的文件来定义那些需被忽略的文件的话,用core.excludesfile 通知 Git 该文件所处的位置,文件内容和.gitignore类似。
把help.autocorrect设置成1,那么在只有一个命令被模糊匹配到的情况下,Git 会自动运行该命令。
color.uiGit会按照你需要自动为大部分的输出加上颜色,你能明确地规定哪些需要着色以及怎样着色,设置color.ui为true来打开所有的默认终端着色。git config --global color.ui true设置好以后,当输出到终端时,Git 会为之加上颜色。其他的参数还有false和always,false意味着不为输出着色,而always则表明在任何情况下都要着色,即使 Git 命令被重定向到文件或管道。
color.*想要具体到哪些命令输出需要被着色以及怎样着色或者 Git 的版本很老,你就要用到和具体命令有关的颜色配置选项,它们都能被置为true、false或always:color.branch,color.diff,color.interactive,color.status,除此之外,以上每个选项都有子选项,可以被用来覆盖其父设置,以达到为输出的各个部分着色的目的。例如,让diff输出的改变信息以粗体、蓝色前景和黑色背景的形式显示:git config --global color.diff.meta “blue black bold”你能设置的颜色值如:normal、black、red、green、yellow、blue、magenta、cyan、white,正如以上例子设置的粗体属性,想要设置字体属性的话,可以选择如:bold、dim、ul、blink、reverse。
merge.tool通知 Git 使用哪个合并工具;mergetool.*.cmd规定命令运行的方式;mergetool.trustExitCode会通知 Git 程序的退出是否指示合并操作成功;diff.external通知 Git 用什么命令做比较。因此,你能运行以下4条配置命令:
|
|
格式化与空白是许多开发人员在协作时,特别是在跨平台情况下,遇到的令人头疼的细小问题。由于编辑器的不同或者Windows程序员在跨平台项目中的文件行尾加入了回车换行符,一些细微的空格变化会不经意地进入大家合作的工作或提交的补丁中。不用怕,Git 的一些配置选项会帮助你解决这些问题。
core.autocrlf假如你正在Windows上写程序,又或者你正在和其他人合作,他们在Windows上编程,而你却在其他系统上,在这些情况下,你可能会遇到行尾结束符问题。这是因为Windows使用回车和换行两个字符来结束一行,而Mac和Linux只使用换行一个字符。虽然这是小问题,但它会极大地扰乱跨平台协作。Git可以在你提交时自动地把行结束符CRLF转换成LF,而在签出代码时把LF转换成CRLF。用core.autocrlf来打开此项功能,如果是在Windows系统上,把它设置成true,这样当签出代码时,LF会被转换成CRLF,git config --global core.autocrlf true。Linux或Mac系统使用LF作为行结束符,因此你不想 Git 在签出文件时进行自动的转换;当一个以CRLF为行结束符的文件不小心被引入时你肯定想进行修正,把core.autocrlf设置成input来告诉 Git 在提交时把CRLF转换成LF,签出时不转换git config --global core.autocrlf input这样会在Windows系统上的签出文件中保留CRLF,会在Mac和Linux系统上,包括仓库中保留LF。如果你是Windows程序员,且正在开发仅运行在Windows上的项目,可以设置false取消此功能,把回车符记录在库中:$ git config --global core.autocrlf false。
core.whitespaceGit预先设置了一些选项来探测和修正空白问题,其4种主要选项中的2个默认被打开,另2个被关闭,你可以自由地打开或关闭它们。默认被打开的2个选项是trailing-space和space-before-tab,trailing-space会查找每行结尾的空格,space-before-tab会查找每行开头的制表符前的空格。默认被关闭的2个选项是indent-with-non-tab和cr-at-eol,indent-with-non-tab会查找8个以上空格(非制表符)开头的行,cr-at-eol让 Git 知道行尾回车符是合法的。设置core.whitespace,按照你的意图来打开或关闭选项,选项以逗号分割。通过逗号分割的链中去掉选项或在选项前加-来关闭,例如,如果你想要打开除了cr-at-eol之外的所有选项:$ git config --global core.whitespace trailing-space,space-before-tab,indent-with-non-tab。当你运行git diff命令且为输出着色时,Git 探测到这些问题,因此你也许在提交前能修复它们,当你用git apply打补丁时同样也会从中受益。如果正准备运用的补丁有特别的空白问题,你可以让 Git 发警告:git apply --whitespace=warn <patch>,或者让 Git 在打上补丁前自动修正此问题:$ git apply --whitespace=fix <patch>。
Git默认情况下不会在推送期间检查所有对象的一致性。虽然会确认每个对象的有效性以及是否仍然匹配SHA-1检验和,但 Git 不会在每次推送时都检查一致性。对于 Git 来说,库或推送的文件越大,这个操作代价就相对越高,每次推送会消耗更多时间,如果想在每次推送时 Git 都检查一致性,设置 receive.fsckObjects 为true来强迫它这么做:git config --system receive.fsckObjects true。
如果对已经被推送的提交历史做衍合,继而再推送,又或者以其它方式推送一个提交历史至远程分支,且该提交历史没在这个远程分支中,这样的推送会被拒绝。这通常是个很好的禁止策略,但有时你在做衍合并确定要更新远程分支,可以在push命令后加-f标志来强制更新。要禁用这样的强制更新功能,可以设置receive.denyNonFastForwards:git config --system receive.denyNonFastForwards true。
规避denyNonFastForwards策略的方法之一就是用户删除分支,然后推回新的引用。git config --system receive.denyDeletes true这样会在推送过程中阻止删除分支和标签 — 没有用户能够这么做。要删除远程分支,必须从服务器手动删除引用文件。
一些设置项也能被运用于特定的路径中,这样,Git 以对一个特定的子目录或子文件集运用那些设置项。这些设置项被称为 Git 属性,可以在你目录中的.gitattributes文件内进行设置(通常是你项目的根目录),也可以当你不想让这些属性文件和项目文件一同提交时,在.git/info/attributes进行设置。使用属性,你可以对个别文件或目录定义不同的合并策略,让 Git 知道怎样比较非文本文件,在你提交或签出前让 Git 过滤内容。你将在这部分了解到能在自己的项目中使用的属性,以及一些实例。让 Git 把所有pbxproj文件当成二进制文件,在.gitattributes文件中设置如下:*.pbxproj -crlf -diff现在,Git 会尝试转换和修正CRLF(回车换行)问题,也不会当你在项目中运行git show或git diff时,比较不同的内容。在Git 1.6及之后的版本中,可以用一个宏代替-crlf -diff:*.pbxproj binary
你不能直接比较两个不同版本的Word文件,除非进行手动扫描,不是吗? Git 属性能很好地解决此问题,把下面的行加到.gitattributes文件:*.doc diff=word。当你要看比较结果时,如果文件扩展名是"doc",Git 调用"word"过滤器。什么是"word"过滤器呢?其实就是 Git 使用strings 程序,把Word文档转换成可读的文本文件,之后再进行比较git config diff.word.textconv strings现在如果在两个快照之间比较以.doc结尾的文件,Git 对这些文件运用"word"过滤器,在比较前把Word文件转换成文本文件。
你还能用这个方法比较图像文件。当比较时,对JPEG文件运用一个过滤器,它能提炼出EXIF信息 — 大部分图像格式使用的元数据。如果你下载并安装了exiftool程序,可以用它参照元数据把图像转换成文本。比较的不同结果将会用文本向你展示:
|
|
使用SVN或CVS的开发人员经常要求关键字扩展。在 Git 中,你无法在一个文件被提交后修改它,因为 Git 会先对该文件计算校验和。然而,你可以在签出时注入文本,在提交前删除它。 Git 属性提供了2种方式这么做。首先,你能够把blob的SHA-1校验和自动注入文件的$Id$字段。如果在一个或多个文件上设置了此字段,当下次你签出分支的时候,Git 用blob的SHA-1值替换那个字段。注意,这不是提交对象的SHA校验和,而是blob本身的校验和:
|
|
下次签出文件时,Git 入了blob的SHA值:
|
|
然而,这样的显示结果没有多大的实际意义。这个SHA的值相当地随机,无法区分日期的前后,所以,如果你在CVS或Subversion中用过关键字替换,一定会包含一个日期值。
因此,你能写自己的过滤器,在提交文件到暂存区或签出文件时替换关键字。有2种过滤器,“clean"和"smudge”。在 .gitattributes文件中,你能对特定的路径设置一个过滤器,然后设置处理文件的脚本,这些脚本会在文件签出前(“smudge”,见图"git-checkout-smudge")和提交到暂存区前(“clean”,见图"git-add-clean")被调用。这些过滤器能够做各种有趣的事。
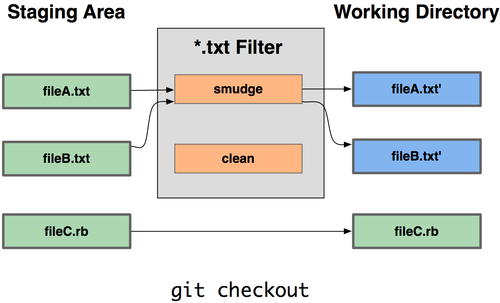
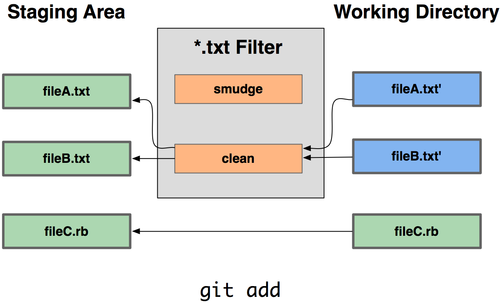
这里举一个简单的例子:在暂存前,用indent(缩进)程序过滤所有C源代码。在.gitattributes文件中设置"indent"过滤器过滤*.c文件:*.c filter=indent。然后,通过以下配置,让 Git 知道"indent"过滤器在遇到"smudge"和"clean"时分别该做什么:
|
|
于是,当你暂存*.c文件时,indent程序会被触发,在把它们签出之前,cat程序会被触发。但cat程序在这里没什么实际作用。这样的组合,使C源代码在暂存前被indent程序过滤,非常有效。
另一个例子是类似RCS的$Date$关键字扩展。为了演示,需要一个小脚本,接受文件名参数,得到项目的最新提交日期,最后把日期写入该文件。下面用Ruby脚本来实现:
|
|
该脚本从git log命令中得到最新提交日期,找到文件中的所有$Date$字符串,最后把该日期填充到$Date$字符串中 — 此脚本很简单,你可以选择你喜欢的编程语言来实现。把该脚本命名为expand_date,放到正确的路径中,之后需要在 Git 中设置一个过滤器(dater),让它在签出文件时调用expand_date,在暂存文件时用Perl清除之:
|
|
这个Perl小程序会删除$Date$字符串里多余的字符,恢复$Date$原貌。到目前为止,你的过滤器已经设置完毕,可以开始测试了。打开一个文件,在文件中输入$Date$关键字,然后设置 Git 属性:
|
|
如果暂存该文件,之后再签出,你会发现关键字被替换了:
|
|
虽说这项技术对自定义应用来说很有用,但还是要小心,因为.gitattributes文件会随着项目一起提交,而过滤器(例如:dater)不会,所以,过滤器不会在所有地方都生效。当你在设计这些过滤器时要注意,即使它们无法正常工作,也要让整个项目运作下去。
Git属性在导出项目归档时也能发挥作用。当产生一个归档时,可以设置 Git 不导出某些文件和目录。如果你不想在归档中包含一个子目录或文件,但想他们纳入项目的版本管理中,你能对应地设置export-ignore属性。
还能对归档做一些简单的关键字替换。可以以--pretty=format形式的简码在任何文件中放入$Format:$ 字符串。例如,如果想在项目中包含一个叫作LAST_COMMIT的文件,当运行git archive时,最后提交日期自动地注入进该文件,可以这样设置:
|
|
运行git archive后,打开该文件,会发现其内容如下:
|
|
通过 Git 属性,还能对项目中的特定文件使用不同的合并策略。一个非常有用的选项就是,当一些特定文件发生冲突,Git 会尝试合并他们,而使用你这边的合并。如果项目的一个分支有歧义或比较特别,但你想从该分支合并,而且需要忽略其中某些文件,这样的合并策略是有用的。例如,你有一个数据库设置文件database.xml,在2个分支中他们是不同的,你想合并一个分支到另一个,而不弄乱该数据库文件,可以设置属性如下:database.xml merge=ours,如果合并到另一个分支,database.xml文件不会有合并冲突,显示如下:
|
|
这样,database.xml会保持原样。
客户端挂钩用于客户端的操作,如提交和合并。服务器端挂钩用于 Git 服务器端的操作,如接收被推送的提交。挂钩都被存储在 Git 目录下的hooks子目录中,即大部分项目中的.git/hooks。 Git 默认会放置一些脚本样本在这个目录中,除了可以作为挂钩使用,这些样本本身是可以独立使用的。所有的样本都是shell脚本,其中一些还包含了Perl的脚本,不过,任何正确命名的可执行脚本都可以正常使用 — 可以用Ruby或Python,或其他。把一个正确命名且可执行的文件放入 Git 目录下的hooks子目录中,可以激活该挂钩脚本,因此,之后他一直会被 Git 调用。
有 4个挂钩被用来处理提交的过程。
-
pre-commit挂钩在键入提交信息前运行,被用来检查即将提交的快照,例如,检查是否有东西被遗漏,确认测试是否运行,以及检查代码。当从该挂钩返回非零值时,Git 放弃此次提交,但可以用git commit –no-verify来忽略。该挂钩可以被用来检查代码错误(运行类似lint的程序),检查尾部空白(默认挂钩是这么做的),检查新方法(译注:程序的函数)的说明。 -
prepare-commit-msg挂钩在提交信息编辑器显示之前,默认信息被创建之后运行。因此,可以有机会在提交作者看到默认信息前进行编辑。该挂钩接收一些选项:拥有提交信息的文件路径,提交类型,如果是一次修订的话,提交的SHA-1校验和。该挂钩对通常的提交来说不是很有用,只在自动产生的默认提交信息的情况下有作用,如提交信息模板、合并、压缩和修订提交等。可以和提交模板配合使用,以编程的方式插入信息。 -
commit-msg挂钩接收一个参数,此参数是包含最近提交信息的临时文件的路径。如果该挂钩脚本以非零退出,Git 放弃提交,因此,可以用来在提交通过前验证项目状态或提交信息。本章上一小节已经展示了使用该挂钩核对提交信息是否符合特定的模式。 -
post-commit挂钩在整个提交过程完成后运行,他不会接收任何参数,但可以运行git log -1 HEAD来获得最后的提交信息。总之,该挂钩是作为通知之类使用的。
提交工作流的客户端挂钩脚本可以在任何工作流中使用,他们经常被用来实施某些策略,但值得注意的是,这些脚本在clone期间不会被传送。可以在服务器端实施策略来拒绝不符合某些策略的推送,但这完全取决于开发者在客户端使用这些脚本的情况。所以,这些脚本对开发者是有用的,由他们自己设置和维护,而且在任何时候都可以覆盖或修改这些脚本。
有3个可用的客户端挂钩用于e-mail工作流。当运行git am命令时,会调用他们,因此,如果你没有在工作流中用到此命令,可以跳过本节。如果你通过e-mail接收由git format-patch产生的补丁,这些挂钩也许对你有用。
-
首先运行的是
applypatch-msg挂钩,他接收一个参数:包含被建议提交信息的临时文件名。如果该脚本非零退出,Git 放弃此补丁。可以使用这个脚本确认提交信息是否被正确格式化,或让脚本编辑信息以达到标准化。 -
下一个在
git am运行期间调用是pre-applypatch挂钩。该挂钩不接收参数,在补丁被运用之后运行,因此,可以被用来在提交前检查快照。你能用此脚本运行测试,检查工作树。如果有些什么遗漏,或测试没通过,脚本会以非零退出,放弃此次git am的运行,补丁不会被提交。 -
最后在
git am运行期间调用的是post-applypatch挂钩。你可以用他来通知一个小组或获取的补丁的作者,但无法阻止打补丁的过程。
其他客户端挂钩
-
pre-rebase挂钩在衍合前运行,脚本以非零退出可以中止衍合的过程。你可以使用这个挂钩来禁止衍合已经推送的提交对象,Git pre-rebase挂钩样本就是这么做的。该样本假定next是你定义的分支名,因此,你可能要修改样本,把next改成你定义过且稳定的分支名。 -
在
git checkout成功运行后,post-checkout挂钩会被调用。他可以用来为你的项目环境设置合适的工作目录。例如:放入大的二进制文件、自动产生的文档或其他一切你不想纳入版本控制的文件。 -
最后,在
merge命令成功执行后,post-merge挂钩会被调用。他可以用来在 Git 无法跟踪的工作树中恢复数据,诸如权限数据。该挂钩同样能够验证在 Git 控制之外的文件是否存在,因此,当工作树改变时,你想这些文件可以被复制。
服务器端挂钩:除了客户端挂钩,作为系统管理员,你还可以使用两个服务器端的挂钩对项目实施各种类型的策略。这些挂钩脚本可以在提交对象推送到服务器前被调用,也可以在推送到服务器后被调用。推送到服务器前调用的挂钩可以在任何时候以非零退出,拒绝推送,返回错误消息给客户端,还可以如你所愿设置足够复杂的推送策略。
-
处理来自客户端的推送(push)操作时最先执行的脚本就是 pre-receive 。它从标准输入(stdin)获取被推送引用的列表;如果它退出时的返回值不是0,所有推送内容都不会被接受。利用此挂钩脚本可以实现类似保证最新的索引中不包含非fast-forward类型的这类效果;抑或检查执行推送操作的用户拥有创建,删除或者推送的权限或者他是否对将要修改的每一个文件都有访问权限。
-
post-receive 挂钩在整个过程完结以后运行,可以用来更新其他系统服务或者通知用户。它接受与 pre-receive 相同的标准输入数据。应用实例包括给某邮件列表发信,通知实时整合数据的服务器,或者更新软件项目的问题追踪系统 —— 甚至可以通过分析提交信息来决定某个问题是否应该被开启,修改或者关闭。该脚本无法组织推送进程,不过客户端在它完成运行之前将保持连接状态;所以在用它作一些消耗时间的操作之前请三思。
-
update 脚本和 pre-receive 脚本十分类似。不同之处在于它会为推送者更新的每一个分支运行一次。假如推送者同时向多个分支推送内容,pre-receive 只运行一次,相比之下 update 则会为每一个更新的分支运行一次。它不会从标准输入读取内容,而是接受三个参数:索引的名字(分支),推送前索引指向的内容的 SHA-1 值,以及用户试图推送内容的 SHA-1 值。如果 update 脚本以退出时返回非零值,只有相应的那一个索引会被拒绝;其余的依然会得到更新。
Git 与其他系统
Git 内部原理
从根本上来讲 Git 是一套内容寻址 (content-addressable) 文件系统。
Git底层命令主要不是用来从命令行手工使用的,更多的是用来为其他工具和自定义脚本服务的。当你在一个新目录或已有目录内执行 git init 时,Git 会创建一个 .git 目录,几乎所有 Git 存储和操作的内容都位于该目录下。如果你要备份或复制一个库,基本上将这一目录拷贝至其他地方就可以了。
config 文件包含了项目特有的配置选项,info 目录保存了一份不希望在 .gitignore 文件中管理的忽略模式 (ignored patterns) 的全局可执行文件。hooks 目录保存了客户端或服务端钩子脚本。另外还有四个重要的文件或目录:HEAD 及 index 文件,objects 及 refs 目录。这些是 Git 的核心部分。objects 目录存储所有数据内容,refs 目录存储指向数据 (分支) 的提交对象的指针,HEAD 文件指向当前分支,index 文件保存了暂存区域信息。
Git 是一套内容寻址文件系统。很不错。不过这是什么意思呢? 这种说法的意思是,Git 从核心上来看不过是简单地存储键值对(key-value)。它允许插入任意类型的内容,并会返回一个键值,通过该键值可以在任何时候再取出该内容。可以通过底层命令 hash-object 来示范这点,传一些数据给该命令,它会将数据保存在 .git 目录并返回表示这些数据的键值。
|
|
|
|
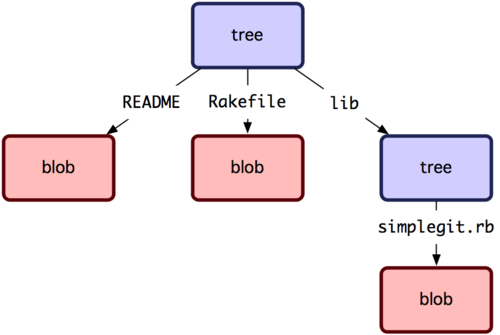
接下去来看 tree 对象,tree 对象可以存储文件名,同时也允许存储一组文件。Git 以一种类似 UNIX 文件系统但更简单的方式来存储内容。所有内容以 tree 或 blob 对象存储,其中 tree 对象对应于 UNIX 中的目录,blob 对象则大致对应于 inodes 或文件内容。一个单独的 tree 对象包含一条或多条 tree 记录,每一条记录含有一个指向 blob 或子 tree 对象的 SHA-1 指针,并附有该对象的权限模式 (mode)、类型和文件名信息。
|
|
master^{tree} 表示 branch 分支上最新提交指向的 tree 对象。请注意 lib 子目录并非一个 blob 对象,而是一个指向别一个 tree 对象的指针:
|
|
|
|
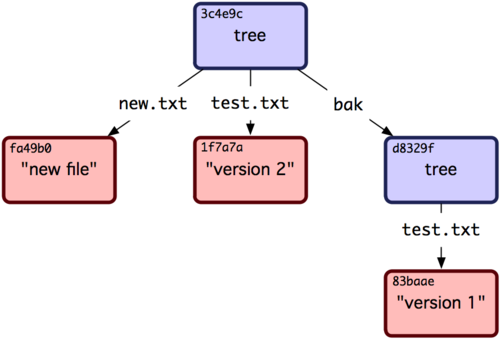
|
|
这基本上就是运行 git add 和 git commit 命令时 Git 进行的工作 ──保存修改了的文件的 blob,更新索引,创建 tree 对象,最后创建 commit 对象,这些 commit 对象指向了顶层 tree 对象以及先前的 commit 对象。这三类 Git 对象 ── blob,tree 以及 commit ── 都各自以文件的方式保存在 .git/objects 目录下。
|
|
|
|
你已经创建了一个正确的 blob 对象。所有的 Git 对象都以这种方式存储,惟一的区别是类型不同 ── 除了字符串 blob,文件头起始内容还可以是 commit 或 tree 。不过虽然 blob 几乎可以是任意内容,commit 和 tree 的数据却是有固定格式的。
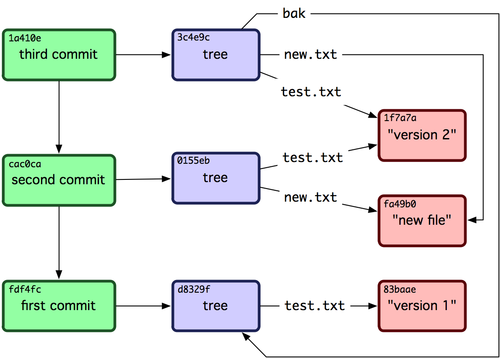
你可以执行像 git log 1a410e 这样的命令来查看完整的历史,但是这样你就要记得 1a410e 是你最后一次提交,这样才能在提交历史中找到这些对象。你需要一个文件来用一个简单的名字来记录这些 SHA-1 值,这样你就可以用这些指针而不是原来的 SHA-1 值去检索了。在 Git 中,我们称之为“引用”(references 或者 refs,译者注)。你可以在 .git/refs 目录下面找到这些包含 SHA-1 值的文件。
|
|
git-update-ref.png
每当你执行 git branch (分支名称) 这样的命令,Git 基本上就是执行 update-ref 命令,把你现在所在分支中最后一次提交的 SHA-1 值,添加到你要创建的分支的引用。
现在的问题是,当你执行 git branch (分支名称) 这条命令的时候,Git 怎么知道最后一次提交的 SHA-1 值呢?答案就是 HEAD 文件。HEAD 文件是一个指向你当前所在分支的引用标识符。这样的引用标识符——它看起来并不像一个普通的引用——其实并不包含 SHA-1 值,而是一个指向另外一个引用的指针。
|
|
Tag 对象非常像一个 commit 对象——包含一个标签,一组数据,一个消息和一个指针。最主要的区别就是 Tag 对象指向一个 commit 而不是一个 tree。它就像是一个分支引用,但是不会变化——永远指向同一个 commit,仅仅是提供一个更加友好的名字。Tag 有两种类型:annotated 和 lightweight 。
|
|
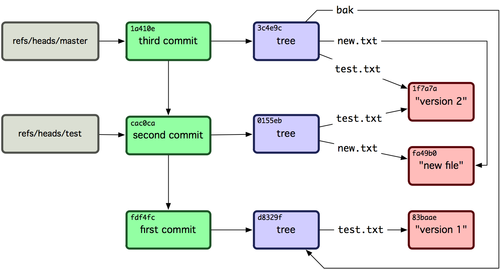
如果你添加了一个 remote 然后推送代码过去,Git 会把你最后一次推送到这个 remote 的每个分支的值都记录在 refs/remotes 目录下。例如,你可以添加一个叫做 origin 的 remote 然后把你的 master 分支推送上去:
|
|
Remote 应用和分支主要区别在于他们是不能被 check out 的。Git 把他们当作是标记这些了这些分支在服务器上最后状态的一种书签。
|
|
你的磁盘上有了两个几乎完全相同的 12K 的对象。如果 Git 只完整保存其中一个,并保存另一个对象的差异内容,岂不更好?事实上 Git 可以那样做。Git 往磁盘保存对象时默认使用的格式叫松散对象 (loose object) 格式。Git 时不时地将这些对象打包至一个叫 packfile 的二进制文件以节省空间并提高效率。当仓库中有太多的松散对象,或是手工调用 git gc 命令,或推送至远程服务器时,Git 都会这样做。手工调用 git gc 命令让 Git 将库中对象打包并看会发生些什么:
|
|
仍保留着的几个对象是未被任何 commit 引用的 blob ── 在此例中是你之前创建的 “what is up, doc?” 和 “test content” 这两个示例 blob。你从没将他们添加至任何 commit,所以 Git 认为它们是 “悬空” 的,不会将它们打包进 packfile 。剩下的文件是新创建的 packfile 以及一个索引。packfile 文件包含了刚才从文件系统中移除的所有对象。索引文件包含了 packfile 的偏移信息,这样就可以快速定位任意一个指定对象。有意思的是运行 gc 命令前磁盘上的对象大小约为 12K ,而这个新生成的 packfile 仅为 6K 大小。通过打包对象减少了一半磁盘使用空间。Git 是如何做到这点的?Git 打包对象时,会查找命名及尺寸相近的文件,并只保存文件不同版本之间的差异内容。可以查看一下 packfile ,观察它是如何节省空间的。git verify-pack 命令用于显示已打包的内容:
|
|
最妙的是可以随时进行重新打包。Git 自动定期对仓库进行重新打包以节省空间。当然也可以手工运行 git gc 命令来这么做。
$ git remote add origin git@github.com:schacon/simplegit-progit.git它在你的 .git/config 文件中添加了一节,指定了远程的名称 (origin), 远程仓库的URL地址,和用于获取操作的 Refspec:
|
|
Refspec 的格式是一个可选的 + 号,接着是 <src>:<dst> 的格式,这里 <src> 是远端上的引用格式, <dst> 是将要记录在本地的引用格式。可选的 + 号告诉 Git 在即使不能快速演进的情况下,也去强制更新它。
缺省情况下 refspec 会被 git remote add 命令所自动生成, Git 会获取远端上 refs/heads/ 下面的所有引用,并将它写入到本地的 refs/remotes/origin/. 所以,如果远端上有一个 master 分支,你在本地可以通过下面这种方式来访问它的历史记录:
|
|
它们全是等价的,因为 Git 把它们都扩展成 refs/remotes/origin/master.如果你想让 Git 每次只拉取远程的 master 分支,而不是远程的所有分支,你可以把 fetch 这一行修改成这样:fetch = +refs/heads/master:refs/remotes/origin/master。这是 git fetch 操作对这个远端的缺省 refspec 值。而如果你只想做一次该操作,也可以在命令行上指定这个 refspec. 如可以这样拉取远程的 master 分支到本地的 origin/mymaster 分支:$ git fetch origin master:refs/remotes/origin/mymaster你也可以在命令行上指定多个 refspec. 像这样可以一次获取远程的多个分支:
|
|
在这个例子中, master 分支因为不是一个可以快速演进的引用而拉取操作被拒绝。你可以在 refspec 之前使用一个 + 号来重载这种行为。
你也可以在配置文件中指定多个 refspec. 如你想在每次获取时都获取 master 和 experiment 分支,就添加两行:
|
|
但是这里不能使用部分通配符,像这样就是不合法的:fetch = +refs/heads/qa*:refs/remotes/origin/qa*
但无论如何,你可以使用命名空间来达到这个目的。如你有一个QA组,他们推送一系列分支,你想每次获取 master 分支和QA组的所有分支,你可以使用这样的配置段落:
|
|
如果你的工作流很复杂,有QA组推送的分支、开发人员推送的分支、和集成人员推送的分支,并且他们在远程分支上协作,你可以采用这种方式为他们创建各自的命名空间。采用命名空间的方式确实很棒,但QA组成员第1次是如何将他们的分支推送到 qa/ 空间里面的呢?答案是你可以使用 refspec 来推送。如果QA组成员想把他们的 master 分支推送到远程的 qa/master 分支上,可以这样运行:$ git push origin master:refs/heads/qa/master如果他们想让 Git 每次运行 git push origin 时都这样自动推送,他们可以在配置文件中添加 push 值:
|
|
这样,就会让 git push origin 缺省就把本地的 master 分支推送到远程的 qa/master 分支上。
你也可以使用 refspec 来删除远程的引用,是通过运行这样的命令:$ git push origin :topic因为 refspec 的格式是 <src>:<dst>, 通过把 <src> 部分留空的方式,这个意思是是把远程的 topic 分支变成空,也就是删除它。
时不时的需要进行一些清理工作 ── 如减小一个仓库的大小,清理导入的库,或是恢复丢失的数据。Git 会不定时地自动运行称为 “auto gc” 的命令。大部分情况下该命令什么都不处理。不过要是存在太多松散对象 (loose object, 不在 packfile 中的对象) 或 packfile,Git 会进行调用 git gc 命令。 gc 指垃圾收集 (garbage collect),此命令会做很多工作:收集所有松散对象并将它们存入 packfile,合并这些 packfile 进一个大的 packfile,然后将不被任何 commit 引用并且已存在一段时间 (数月) 的对象删除。$ git gc --auto再次强调,这个命令一般什么都不干。如果有 7,000 个左右的松散对象或是 50 个以上的 packfile,Git 才会真正调用 gc 命令。可能通过修改配置中的 gc.auto 和 gc.autopacklimit 来调整这两个阈值。
在使用 Git 的过程中,有时会不小心丢失 commit 信息。这一般出现在以下情况下:强制删除了一个分支而后又想重新使用这个分支,hard-reset 了一个分支从而丢弃了分支的部分 commit。如果这真的发生了,有什么办法把丢失的 commit 找回来呢?下面的示例演示了对 test 仓库主分支进行 hard-reset 到一个老版本的 commit 的操作,然后恢复丢失的 commit 。首先查看一下当前的仓库状态:
|
|
接着将 master 分支移回至中间的一个 commit:
|
|
这样就丢弃了最新的两个 commit ── 包含这两个 commit 的分支不存在了。现在要做的是找出最新的那个 commit 的 SHA,然后添加一个指它它的分支。关键在于找出最新的 commit 的 SHA ── 你不大可能记住了这个 SHA,是吧?
通常最快捷的办法是使用 git reflog 工具。当你 (在一个仓库下) 工作时,Git 会在你每次修改了 HEAD 时悄悄地将改动记录下来。当你提交或修改分支时,reflog 就会更新。git update-ref 命令也可以更新 reflog,这是在本章前面的 “Git References” 部分我们使用该命令而不是手工将 SHA 值写入 ref 文件的理由。任何时间运行 git reflog 命令可以查看当前的状态:
|
|
可以看到我们签出的两个 commit ,但没有更多的相关信息。运行 git log -g 会输出 reflog 的正常日志,从而显示更多有用信息:
|
|
看起来弄丢了的 commit 是底下那个,这样在那个 commit 上创建一个新分支就能把它恢复过来。比方说,可以在那个 commit (ab1afef) 上创建一个名为 recover-branch 的分支:
|
|
酷!这样有了一个跟原来 master 一样的 recover-branch 分支,最新的两个 commit 又找回来了。接着,假设引起 commit 丢失的原因并没有记录在 reflog 中 ── 可以通过删除 recover-branch 和 reflog 来模拟这种情况。这样最新的两个 commit 不会被任何东西引用到:
|
|
因为 reflog 数据是保存在 .git/logs/ 目录下的,这样就没有 reflog 了。现在要怎样恢复 commit 呢?办法之一是使用 git fsck 工具,该工具会检查仓库的数据完整性。如果指定 --full 选项,该命令显示所有未被其他对象引用 (指向) 的所有对象:
|
|
本例中,可以从 dangling commit 找到丢失了的 commit。用相同的方法就可以恢复它,即创建一个指向该 SHA 的分支。
Git 有许多过人之处,不过有一个功能有时却会带来问题:git clone 会将包含每一个文件的所有历史版本的整个项目下载下来。如果项目包含的仅仅是源代码的话这并没有什么坏处,毕竟 Git 可以非常高效地压缩此类数据。不过如果有人在某个时刻往项目中添加了一个非常大的文件,那们即便他在后来的提交中将此文件删掉了,所有的签出都会下载这个大文件。因为历史记录中引用了这个文件,它会一直存在着。当你将 Subversion 或 Perforce 仓库转换导入至 Git 时这会成为一个很严重的问题。在此类系统中,(签出时) 不会下载整个仓库历史,所以这种情形不大会有不良后果。如果你从其他系统导入了一个仓库,或是发觉一个仓库的尺寸远超出预计,可以用下面的方法找到并移除大 (尺寸) 对象。警告:此方法会破坏提交历史。为了移除对一个大文件的引用,从最早包含该引用的 tree 对象开始之后的所有 commit 对象都会被重写。如果在刚导入一个仓库并在其他人在此基础上开始工作之前这么做,那没有什么问题 ── 否则你不得不通知所有协作者 (贡献者) 去衍合你新修改的 commit 。为了演示这点,往 test 仓库中加入一个大文件,然后在下次提交时将它删除,接着找到并将这个文件从仓库中永久删除。首先,加一个大文件进去:
|
|
喔,你并不想往项目中加进一个这么大的 tar 包。最后还是去掉它:
|
|
对仓库进行 gc 操作,并查看占用了空间:
|
|
可以运行 count-objects 以查看使用了多少空间:
|
|
size-pack 是以千字节为单位表示的 packfiles 的大小,因此已经使用了 2MB 。而在这次提交之前仅用了 2K 左右 ── 显然在这次提交时删除文件并没有真正将其从历史记录中删除。每当有人复制这个仓库去取得这个小项目时,都不得不复制所有 2MB 数据,而这仅仅因为你曾经不小心加了个大文件。当我们来解决这个问题。
首先要找出这个文件。在本例中,你知道是哪个文件。假设你并不知道这一点,要如何找出哪个 (些) 文件占用了这么多的空间?如果运行 git gc,所有对象会存入一个 packfile 文件;运行另一个底层命令 git verify-pack 以识别出大对象,对输出的第三列信息即文件大小进行排序,还可以将输出定向到 tail 命令,因为你只关心排在最后的那几个最大的文件:
|
|
最底下那个就是那个大文件:2MB 。要查看这到底是哪个文件,可以使用第 7 章中已经简单使用过的 rev-list 命令。若给 rev-list 命令传入 –objects 选项,它会列出所有 commit SHA 值,blob SHA 值及相应的文件路径。可以这样查看 blob 的文件名:
|
|
接下来要将该文件从历史记录的所有 tree 中移除。很容易找出哪些 commit 修改了这个文件:
|
|
必须重写从 6df76 开始的所有 commit 才能将文件从 Git 历史中完全移除。这么做需要用到第 6 章中用过的 filter-branch 命令:
|
|
–index-filter 选项类似于–tree-filter 选项,但这里不是传入一个命令去修改磁盘上签出的文件,而是修改暂存区域或索引。不能用 rm file 命令来删除一个特定文件,而是必须用 git rm –cached 来删除它 ── 即从索引而不是磁盘删除它。这样做是出于速度考虑 ── 由于 Git 在运行你的 filter 之前无需将所有版本签出到磁盘上,这个操作会快得多。也可以用 –tree-filter 来完成相同的操作。git rm 的 –ignore-unmatch 选项指定当你试图删除的内容并不存在时不显示错误。最后,因为你清楚问题是从哪个 commit 开始的,使用 filter-branch 重写自 6df7640 这个 commit 开始的所有历史记录。不这么做的话会重写所有历史记录,花费不必要的更多时间。
现在历史记录中已经不包含对那个文件的引用了。不过 reflog 以及运行 filter-branch 时 Git 往 .git/refs/original 添加的一些 refs 中仍有对它的引用,因此需要将这些引用删除并对仓库进行 repack 操作。在进行 repack 前需要将所有对这些 commits 的引用去除:
|
|
看一下节省了多少空间。
|
|
repack 后仓库的大小减小到了 7K ,远小于之前的 2MB 。从 size 值可以看出大文件对象还在松散对象中,其实并没有消失,不过这没有关系,重要的是在再进行推送或复制,这个对象不会再传送出去。如果真的要完全把这个对象删除,可以运行 git prune --expire 命令。
Refs: